 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-UAVBench: How Well Do Multimodal Large Language Models See, Think, and Plan in Low-Altitude UAV Scenarios?
Dec 29, 2025While Multimodal Large Language Models (MLLMs) have exhibited remarkable general intelligence across diverse domains, their potential in low-altitude applications dominated by Unmanned Aerial Vehicles (UAVs) remains largely underexplored. Existing MLLM benchmarks rarely cover the unique challenges of low-altitude scenarios, while UAV-related evaluations mainly focus on specific tasks such as localization or navigation, without a unified evaluation of MLLMs'general intelligence. To bridge this gap, we present MM-UAVBench, a comprehensive benchmark that systematically evaluates MLLMs across three core capability dimensions-perception, cognition, and planning-in low-altitude UAV scenarios. MM-UAVBench comprises 19 sub-tasks with over 5.7K manually annotated questions, all derived from real-world UAV data collected from public datasets. Extensive experiments on 16 open-source and proprietary MLLMs reveal that current models struggle to adapt to the complex visual and cognitive demands of low-altitude scenarios. Our analyses further uncover critical bottlenecks such as spatial bias and multi-view understanding that hinder the effective deployment of MLLMs in UAV scenarios. We hope MM-UAVBench will foster future research on robust and reliable MLLMs for real-world UAV intelligence.
DeepPerception: Advancing R1-like Cognitive Visual Perception in MLLMs for Knowledge-Intensive Visual Grounding
Mar 17, 2025Human experts excel at fine-grained visual discrimination by leveraging domain knowledge to refine perceptual features, a capability that remains underdeveloped in current Multimodal Large Language Models (MLLMs). Despite possessing vast expert-level knowledge, MLLMs struggle to integrate reasoning into visual perception, often generating direct responses without deeper analysis. To bridge this gap, we introduce knowledge-intensive visual grounding (KVG), a novel visual grounding task that requires both fine-grained perception and domain-specific knowledge integration. To address the challenges of KVG, we propose DeepPerception, an MLLM enhanced with cognitive visual perception capabilities. Our approach consists of (1) an automated data synthesis pipeline that generates high-quality, knowledge-aligned training samples, and (2) a two-stage training framework combining supervised fine-tuning for cognitive reasoning scaffolding and reinforcement learning to optimize perception-cognition synergy. To benchmark performance, we introduce KVG-Bench a comprehensive dataset spanning 10 domains with 1.3K manually curated test cases. Experimental results demonstrate that DeepPerception significantly outperforms direct fine-tuning, achieving +8.08\% accuracy improvements on KVG-Bench and exhibiting +4.60\% superior cross-domain generalization over baseline approaches. Our findings highlight the importance of integrating cognitive processes into MLLMs for human-like visual perception and open new directions for multimodal reasoning research. The data, codes, and models are released at https://github.com/thunlp/DeepPerception.
TripleRE: Knowledge Graph Embeddings via Tripled Relation Vectors
Sep 17, 2022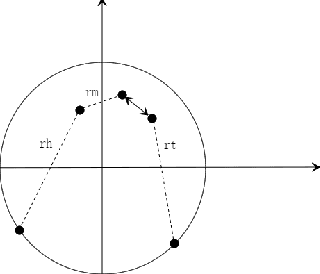
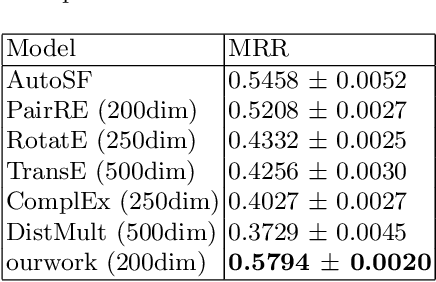

Translation-based knowledge graph embedding has been one of the most important branches for knowledge representation learning since TransE came out. Although many translation-based approaches have achieved some progress in recent years, the performance was still unsatisfactory. This paper proposes a novel knowledge graph embedding method named TripleRE with two versions. The first version of TripleRE creatively divide the relationship vector into three parts. The second version takes advantage of the concept of residual and achieves better performance. In addition, attempts on using NodePiece to encode entities achieved promising results in reducing the parametric size, and solved the problems of scalability. Experiments show that our approach achieved state-of-the-art performance on the large-scale knowledge graph dataset, and competitive performance on other datasets.